
Pushing the Speed Limit: Designing SerDes Transceivers for the 224 and 448Gbps Scaling Era
An architectural analysis of DSP-driven SerDes datapaths, current-steering nonidealities, and the multi-phase clock constraints breaking modern wireline links.

Editor’s Note (5/30/26): Moving forward, I am transitioning this Substack into a deep-dive resource on System Architecture that covers the packaging, thermal, power, and signal integrity stack. To reflect the depth of the synthesis and combination of topics involved, the deepest technical layers of each of my guides will now be reserved for paid subscribers.
Before each paywall, I’ll post links to some of my other adjacent posts that give you a well rounded flavor of the interactions amongst other domains.
As data speeds climb from 112Gbps to 224Gbps and 448Gbps, data starting running into physics constraints and transceivers become more complex to compensate for these effects.
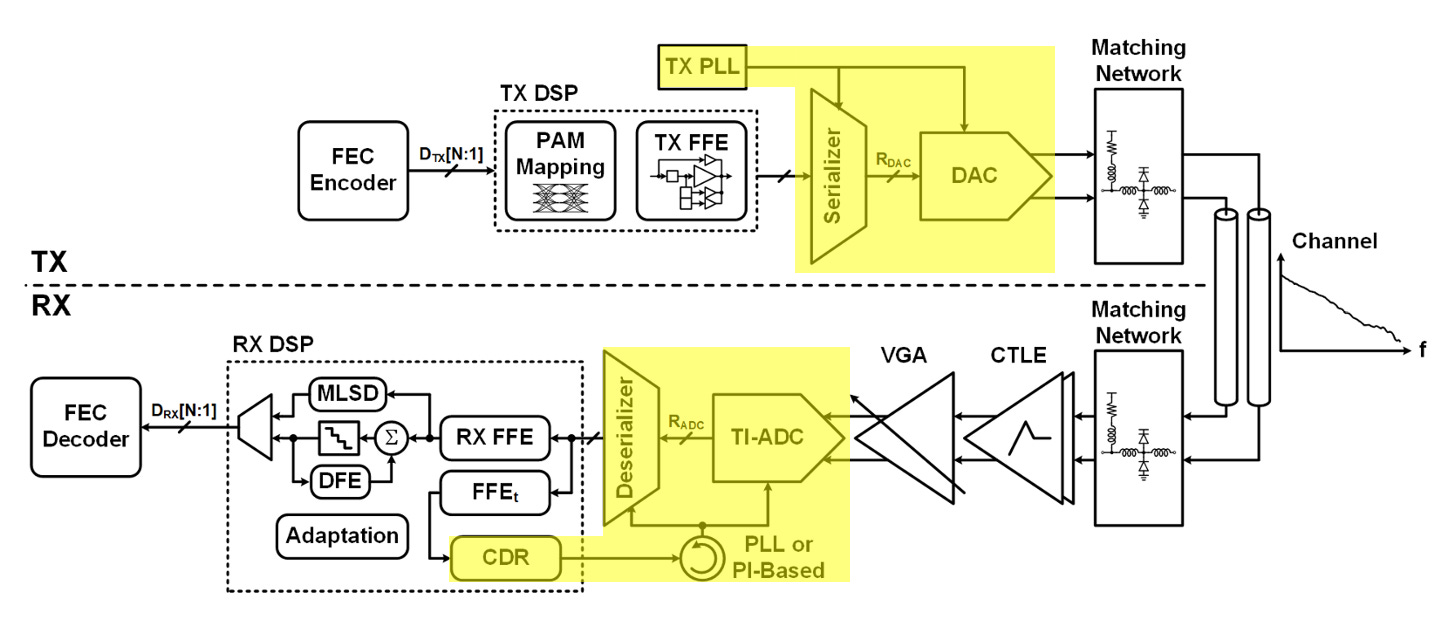
In this post I’ll be doing a system architecture breakdown of a modern DSP-based transceiver. I’ll explain the underlying physics constraints and the major blocks data passes through. Then, I’ll do a deep dive into the high-speed building blocks (shown in yellow) on the TX and RX side. I’ll be covering the following:
The real problem: increasing data throughput under physical limits
System Datapath overview
TX Architecture:
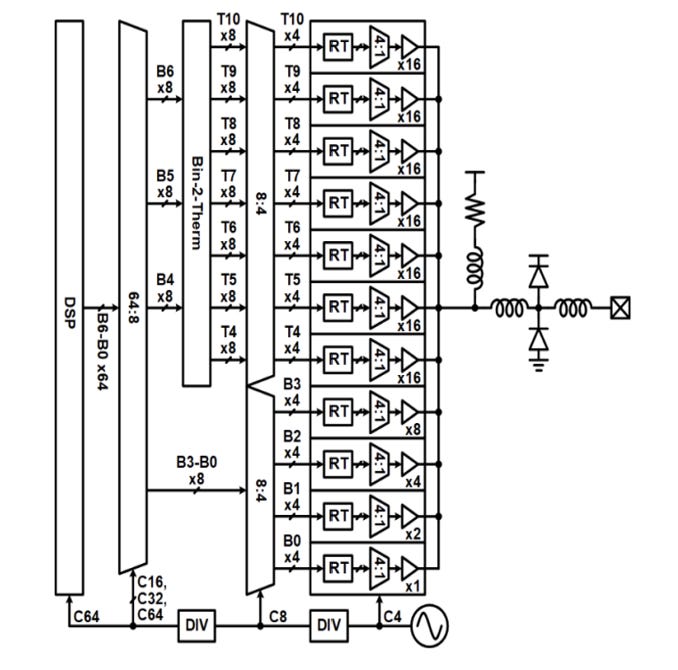
Serializer / Mux tree
DAC - 6-7 Bit current steering DAC
RX Side - Time-Interleaved ADC
🔒Clocking Architecture
🔒Clock Recovery: Bang Bang Phase Detector
🔒Clock Generation: LC-VCO Based PLL
🔒Multi-phase clock generation: The phase Interpolator
🔒Clock Distribution: Repeater, transmission line, and resonator-based
Most of the figures in these slides are from the ISSCC tutorials as well as the papers in the references.
The real problem: increasing data throughput under physical limits
As data rates climb, we need to ask ourselves: what fundamentally constraints the data speed from first principles?
Data speed is now limited by physics and device parameters on the chip, which include, but not limited to, the following:
Channel Loss: Loss scales with signal frequency, and high frequency attenuation rounds out the sharp edges of digital signals
High impedance nodes in analog circuits: Active loads have a high input resistance, which is good for gain, but also creates dominant poles that lower overall BW.
On-Chip Capacitance: Bigger transistors have bigger C that can affect rise/fall times of signals
Noise / Jitter: The randomness in clock / data edges affect how fast those signals can be relative to the clock period. This impacts reliability of high speed digital circuits and time-interleaved switches
What tricks do designers have to increase speed? I contend there are two major paradigm shifts:
Current steering circuits: These circuits steer constant currents through switches to a resistive load. The main advance is that it minimizes charging/discharging time of parasitic capacitors. However, current steering circuits tend to consume more power than equivalent charged-based topologies.
Time interleaving: Instead of making a single component faster, place many in parallel and distribute data through “ranks” of S/H and T/H switches. Time interleaving introduces added complexity in clocks to coordinate parallel operations
System Datapath overview
Next lets look at the major blocks in the datapath.
The function of a transceiver is quite simple: transmit a large amount of data from the TX and RX with minimal errors across a medium as fast as possible.
For short reach, low speed operation, the architecture relied mostly on analog blocks. However, due to recent data demands, one of the big paradigm shifts is a move to digital for the processing. Digital is great at performing parallel processing of data at a moderate clock (1-10’s GHz) frequency.

However, when it comes to data transmission, edge density becomes the constraint. You can only pack so much circuitry to drive the parallel channels on the edge of a chip and copper cables in the system.
As a result, data transmission favors serialized data at a high speed to pack as much data density as possible and transmit on a single cable.
These constraints influence the architecture of modern wireline transceivers.
On the TX Side, the main high speed blocks include:
Forward Error Encoding (FEC) - Encodes the data with parity bits that correct for channel error at the RX side
Feed Forward Equalization (FFE) - Pre-distorts the signal using a FIR filter to compensate for channel losses
Serializer - Serializes the digital data from multiple channels and raises the effective output rate. 112 Gb/s PAM4 corresponds to a 56 GBd symbol rate, though practical serializers often use half-rate or quarter-rate architectures that are time-interleaved
High-speed DAC - turns digital symbols into an analog waveform
Driver - amplitudes the signal before it is transmitted on the channel
In the Channel:
Matching network - matches the TX and RX to the characteristic impedance to avoid reflections and transmission line effects
Channel - attenuates and distorts the transmitted signal
In the RX:
Receiver front-end - conditions the signal by amplifying it (variable gain amplifier) and providing equalization (CTLE)
TI-ADC - converts the analog value to digital values
Deserializer - converts the digitized data from the transmission rate to the digital frequency
DSP - processes and recovers data
As a result of the added digital complexity, high speed and parallel processing blocks require a robust clock architecture to synchronize the data properly.
In the following sections, we’ll step through each of the high speed blocks, with the principle of operation, the key impairments, and how they affect the system level.
TX Architecture
Serializer / Mux tree
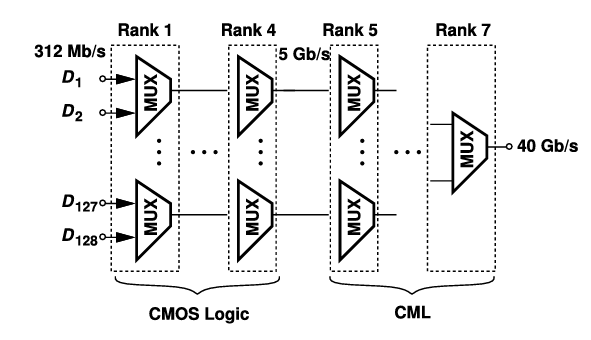
The mux tree is used for serializing / deserializing data. Here, stages of 2-1 muxes are arranged in ranks. This ensure each interconnect between muxes aren’t heavily loaded that can slow down operation.
The final rank operates with the highest-rate clock, while earlier ranks use divided versions of that clock so that each stage runs at a rate compatible with its local data rate.
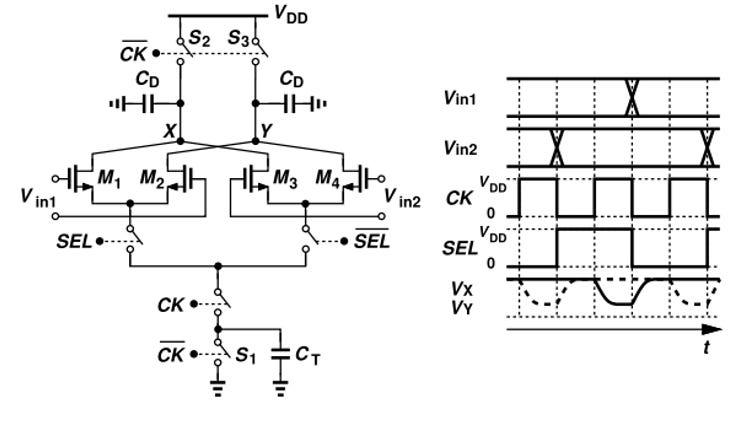
A common high-speed mux cell is the current steering mux cell. This cell uses two differential pairs for each of the inputs. To select each input, the SEL signal, synchronized to the CLK, steers the current between the two input branches.
Impairments
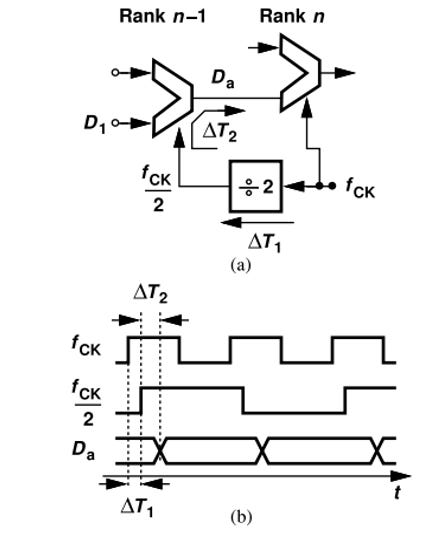
Kickback noise from clock feedthrough. Clock feedthrough and switching transients can disturb internal common-mode nodes and degrade timing margin, especially in the final high-speed stages.
Skew between SEL and clk.
Skew between stages in the MUX tree. The accumulated clock delay associated with the driver and the mux itself can cause ranks to fail to clock the data fast enough.
DAC - 6-7 Bit current steering DAC
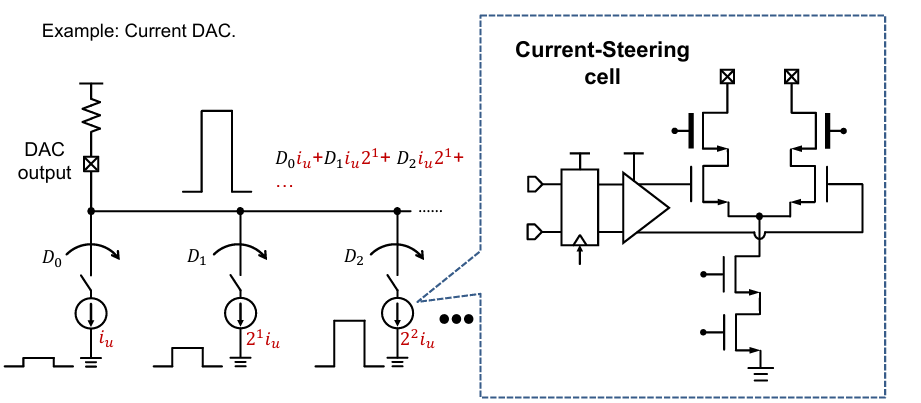
The high speed DAC commonly employs a segmented current steering architecture. This architecture uses scaled current sources representing the “weight” of the binary bits. The steered currents are summed and converted to an output voltage across a load impedance.
The current steering cell consist of two main branches and a selector with a flip flop and driver. This current source is generated from the bottom two transistors. The driver cell “steers” this current between two branches: the left branch to enable the bit and right branch to disable it. The switch control is retimed so current steering occurs with precise timing at the symbol rate.
Current continuity is often preferred for high speed because it minimizes voltage swings from constantly charging / discharging capacitive nodes. However, it also consumes static power even when the bit is disabled.
This current cell is then scaled to a segmented architecture, which uses both unary and binary DACs. Unary (or thermometer code) uses unit-sized current sources arrayed in a 2x2 grid in layout to achieve better matching of current sources.
In many wireline transmitters, DAC resolution is kept modest, often around 6–7 bits, because channel loss, jitter, and front-end noise dominate before very fine quantization does.
Impairments
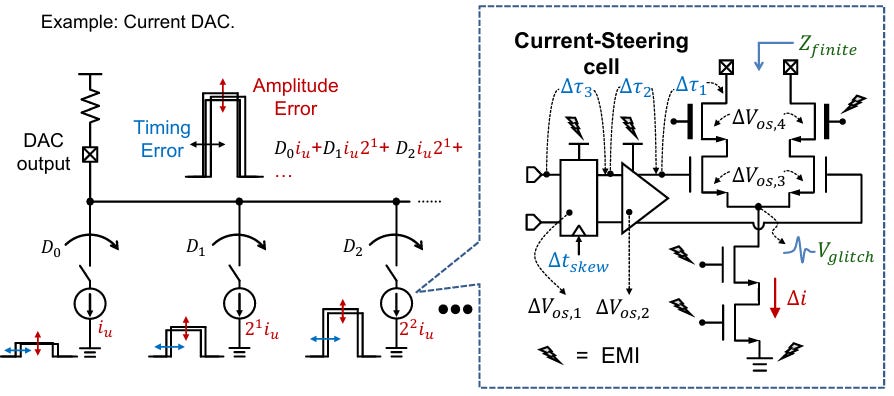
There are several impairments that cause both timing and amplitude errors:
Time delay
Voltage glitches
Clock Skew
Finite Input impedance
EMI at all sources
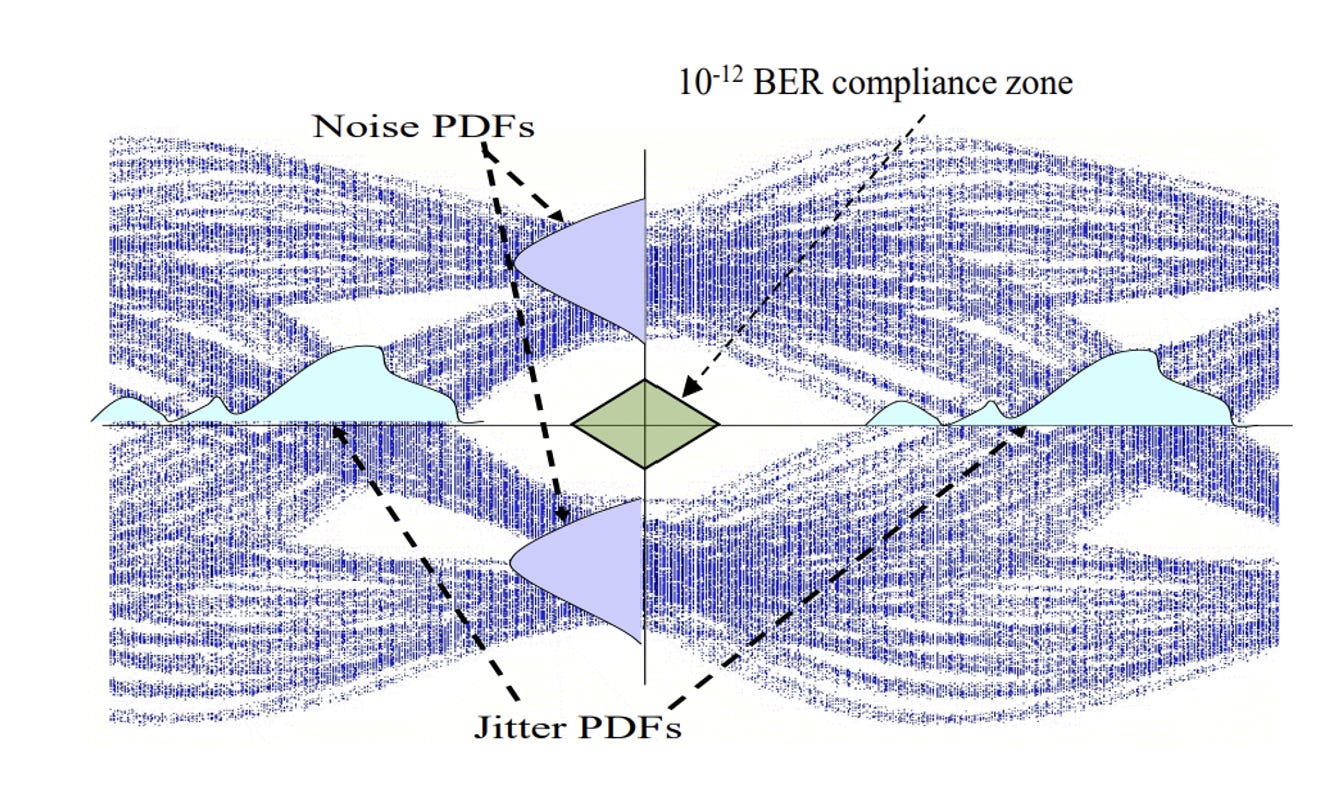
Figure 9. Jitter and Noise PDFs and how the affect BER.
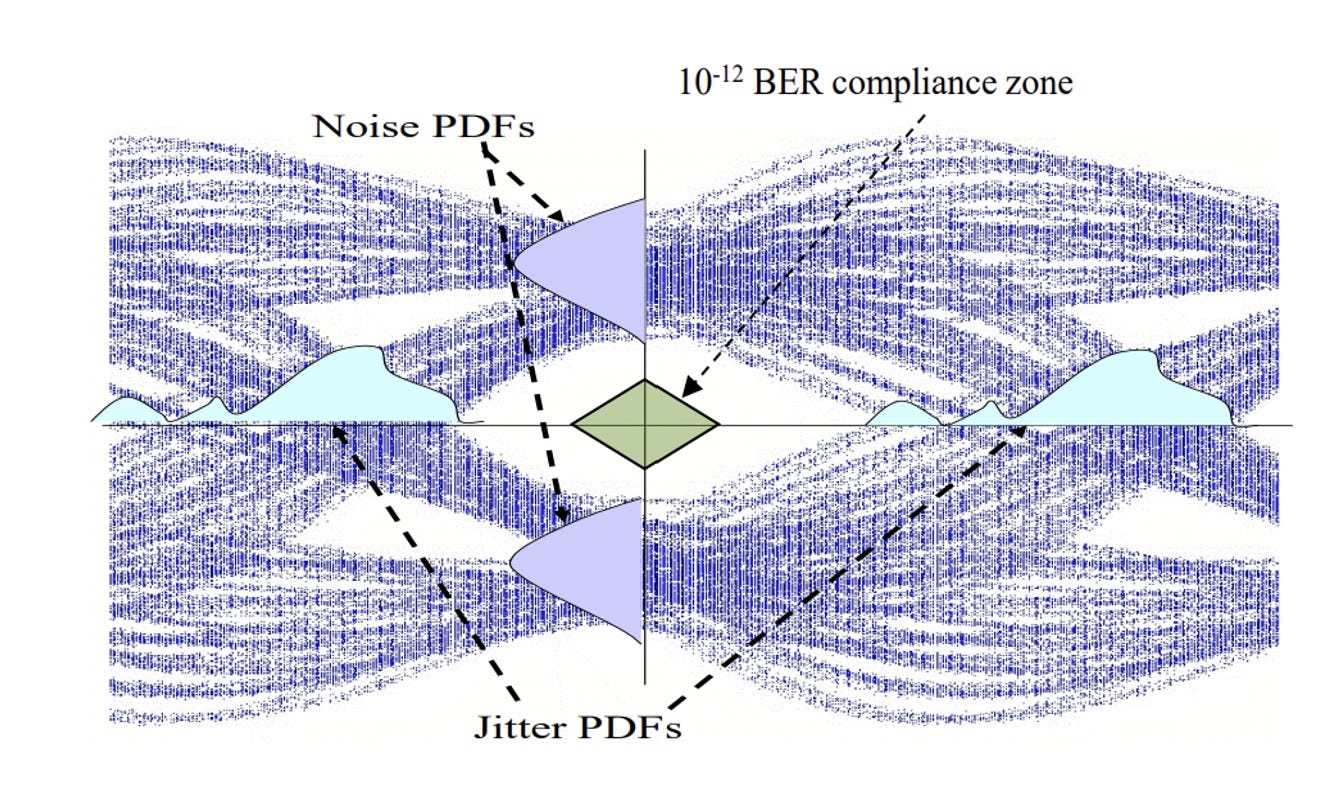
These impairments introduce timing and amplitude error at the system level. They translates to jitter in the x domain and noise in the y dimension. These effects directly affect the size of the “eye” at the RX side, so it is important to account for these and spec these appropriately.
RX Side - Time-Interleaved ADC
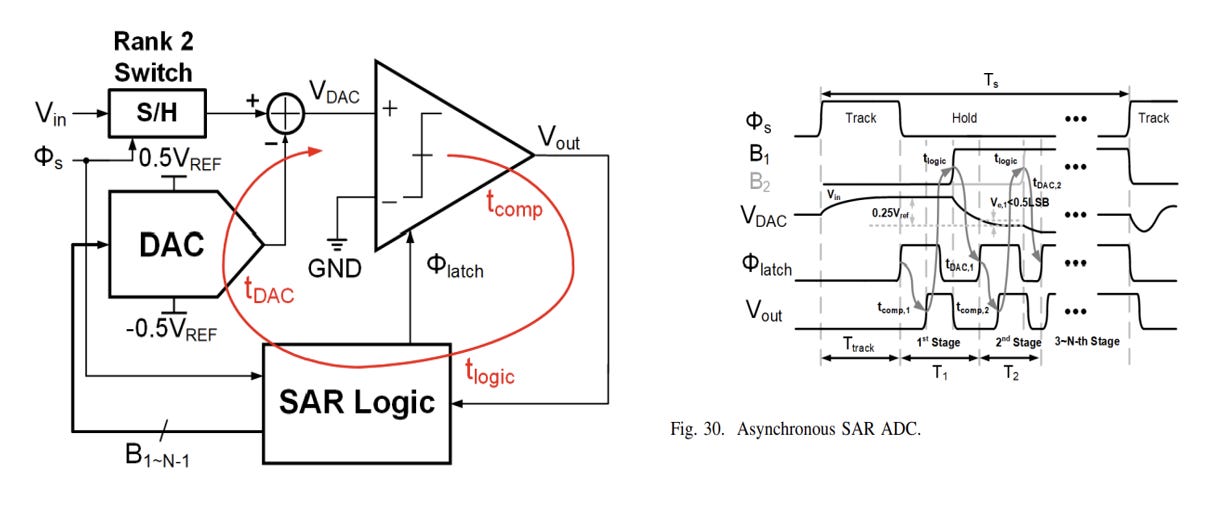
A common modern RX approach uses time-interleaved asynchronous SAR ADCs operating in a self-clocked manner.
In normal asynchronous SARs, it takes N clock cycles to complete an N bit conversion. In asynchronous circuits, self-clocking allows the completion of one comparison to automatically trigger the next.
Self-clocking removes the need for a very high external clock, but it makes the conversion timing dependent on timing delays and handshake robustness.
Asynchronous SARs are commonly used due to low comparator count, simple digital logic, and capacitive DACs for energy efficient operation at typical 6-7 bit resolution.
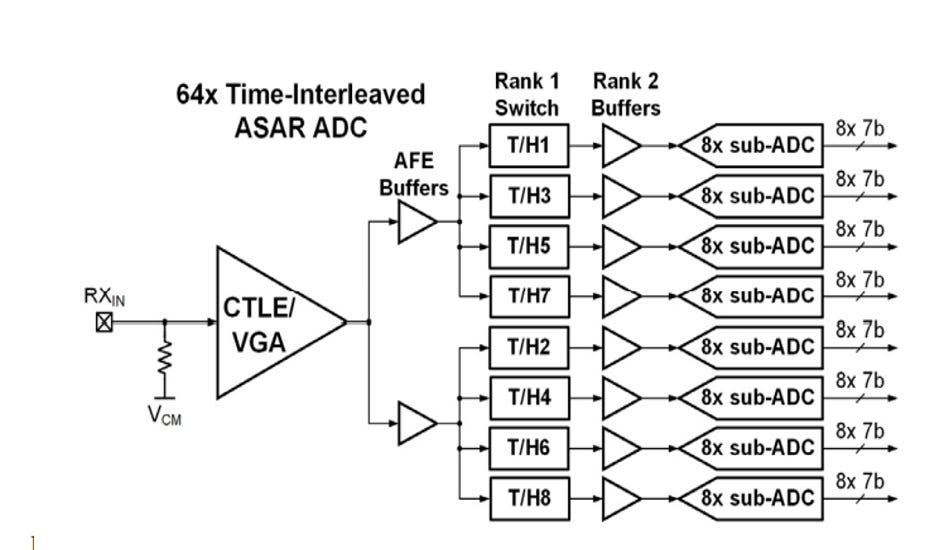
These SAR ADCs are time interleaved. The high speed data is “fanned out” to each of the sub-ADCs in order for their analog values to be digitalized. This is accomplished through a two-rank NxM interleaving scheme. This architecture performs sampling in two ranks:
Rank 1 - Track and hold. The first rank tracks and holds the signal. The performance of these switches are critical as they sample the full BW signal.
Rank 2 - Sample and hold buffer. These buffer the T/H signals to drive the parallel ADCs.
In modern PAM-4 112Gbps, the interleave factors range from 36-128 sub-ADCs depending on the layout area, with 64 being common. [1]
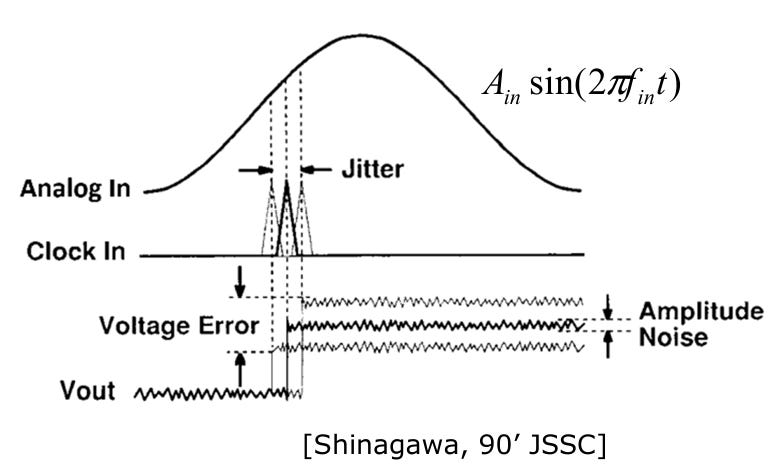
Impairments: There are several impairments:
Skew and Jitter of clock
Mismatches between sub-ADCs
These impairments translate timing mismatches into sampled voltage errors, often in a signal-dependent way, and can create both noise-like degradation and spurious tones.
Clocking Architecture
Perhaps the most important part of a high speed chip is the one everyone takes for granted: The clock.
The clock distribution becomes an increasingly important constraint as dimensions and speeds have scaled down. There are several challenges the clock faces:
The clock needs to be recovered from the asynchronous RX data to ensure that the clock is in “sync” with the data to clock it appropriately
The VCO needs to generate a reference clock with low jitter
The time-interleaved blocks need some form of multi-phase clock to synchronize operations across parallel processing elements cleanly
The parallel clock distribution needs minimal skew to minimize mismatches
After the pay wall I’ll describe the clocking architecture in more detail.
If you want to get a flavor for the adjacent domains involved, I have several other posts to check out as well:


