
From Atari to ChatGPT: The Technical and Corporate Forces Shaping Frontier AI
How the intersection of scientific ambition, commercial urgency, and safety research birthed the modern scaling era.

Demis Hassabis is perhaps one of the most important influences in Modern AI that isn’t a household name.
Modern AI is not just a story of better models. It was shaped by the interaction between scientific ambition, commercial urgency, safety concerns, and the compute power available to model it.
Every AI enthusiast should read “The Infinity Machine” to better understand the development of modern AI. It tells the story of Demis Hassabis, CEO of Google DeepMind, from his origins, to his founding of DeepMind and its acquisition by Google.
I’ll highlight a brief history of AI through the formative years of Demis Hassabis, and cover the key technical developments and organizational challenges along the path to modern AI, particularly around AI safety.
I’ll also dive into the key papers addressed in the book that influence modern AI today such as deep reinforcement learning, transformer architecture, and chain-of-thought prompting that approximate human intuition.
Demis Hassabis
From his early days Demis Hassabis is a modern example of a modern day Polymath, with broad-ranging interests from sci-fi, philosophy, computer science, and neuroscience.
His entire career has been dedicated to developing artificial general intelligence (AGI), a hypothetical type of AI that matches or exceeds human cognitive abilities across a wide range of tasks. His dedication to this mission has him referred to as an “authentic entrepreneur” by VCs because he is genuinely dedicated to a cause, as opposed to entrepreneurs fishing for ideas to strike it rich.
We’ll see through his formative years in video game development about how he distinguishes between early machine vs human intelligence:
Early machine intelligence uses deductive, first order reasoning to reason through problems
Human intelligence generally uses induction or high level pattern recognition to identify shapes, sounds, and reason through sentences
Formative Years
Demis had a fairly modest upbringing in North London. When he was young he was highly influenced by classic Sci-Fi: “Enders Game”, “Foundation”, “Godel, Escher, Bach” and Ian Banks “Culture” series were some of his early influences. He was a chess genius and video game enthusiast in his early days, frequently ruminating on what algorithms are needed to program a machine to play chess.
He won admission at University of Cambridge to study CS, but he was too young at the age of 16. During this time gap, he worked on video game development at Bullfrog with Peter Molyneux to develop video games, including Theme Park.
After he graduated, he founded Elixir Studios in 1998, a London-based video games developer, and work on developing video games that focused on complex decisions on the user’s part, including Republic: The Revolution and Evil Genius.
Elixir Studios ultimately failed in April 2005, at which point he decided to pursue his PhD in neuroscience at University College London (UCL) from 2005 to 2009. His studies focused on the field of imagination, memory, and amnesia.
After he obtained his PhD, Demis Hassabis founded DeepMind Technologies in London in 2010, a ML AI startup with Shane Legg and Mustafa Suleyman. The goal is to combine insights from neuroscience with ML and computing hardware to create new algorithms to advance toward AGI. His company was successful at training a Deep Q-Network to play Atari games in 2013. [1]
In 2014, Google purchased DeepMind for $400 million where it remained a separate, siloed entity from Google. Since being purchased, it racked up a list of accomplishments from 2014 to 2020:
It created a clinical alert system, Streams, for acute kidney injury in the UK. While well intended, it was controversial because of concerns over patient data governance.
It created AlphaGo, a program that played Go. It defeated world champion Lee Sedol in 2016 and several other high level players with moves that humans had very little intuition for.
It created AlphaFold and AlphaFold 2 to take on the CASP protein-structure prediction competitions. AlphaFold 2 achieved a breakthrough at CASP14 in 2020. In 2021, DeepMind and EMBL-EBI launched the AlphaFold Protein Structure Database, and by 2022 it included predictions for more than 200 million protein structures. Hassabis later won a Nobel Prize in Chemistry for his contribution, along with John Jumper and David Baker.

AI Safety: Commercial time-to-market vs Research Discovery
While DeepMind racked up an impressive list of accomplishments in its early years, it entered a ferocious competition to develop LLMs against OpenAI, led by Sam Altman.
Much of the story that follows revolves around two concepts:
AI safety
Research vs Commercial Environments
I’ll cover the groundwork for each concept, then dive into the high level narrative of the competition between OpenAI and DeepMind.
AI Safety

Long before AI safety became a technical field, Sci-Fi gave the public a meaningful way to think about machine intelligence and control. “I, Robot” by Isaac Asimov in 1950, proposed the “the Three Laws of Robotics” that dictate that “robots must never harm humans, must obey orders unless they conflict with the first law, and must protect their own existence”. Additionally, classic Sci-Fi highlights the potential dangers of misuse of AI such as Terminator, Blade Runner, and Cyberpunk genres.
These examples influenced the development of AI where humans ensure that AI is safe and aligned with human intentions. Humans need to ensure that AI doesn’t deceive users by providing harmful / misleading information.
One way to test for AI safety is through adversarial testing, or “red teaming”, where human testers act as adversaries to intentionally break, deceive, or trigger harmful outputs from AI systems. Red teams simulate real-world attacks to identify safety, security, and ethical flaws, such as prompt injections, bias, or data leakage, before malicious actors exploit them.
As AI models scaled in complexity, they became harder to interpret. Inputs could be fed in during training and outputs could be evaluated during inference, but the internal representations became increasingly difficult to explain. AI can produce human-aligned outputs 99.9% of the time, but identifying the 0.1% of cases where it acts against human intentions can be difficult.
Red teaming alone does not guarantee total safety, but is one tool in a broad range of strategies to ensure that AI is aligned with human intentions.
Research vs Commercial incentives
In large tech corporations such as Google, there are two main categories of groups that contribute to business revenues:
Revenue-generating core business - Engineers who create products to take to market or maintain/update existing infrastructure. Here, work is considered to be low risk and execution on set priorities is important.
Research and development - Researchers who work on high-risk, long-term, and ambitious ventures. In R&D environments, ideas are incubated to either be published or folded into products to take to market.
Organizations consist of groups that range from commercial readiness vs research focus that help sustain the revenue of the core business as well as bet on “moonshot” ideas that can generate revenue in the future.
In 2015, Google restructured under the umbrella holding company “Alphabet”, separating its core businesses from longer-term moonshot bets such as autonomous driving, fiber, and life sciences. This move positioned Google to overcome the “innovators dilemma” by incubating capabilities to enhance its core business or act as additional revenue generating streams in the future should outside disrupters arrive and threaten it.
DeepMind, HQed in London, was acquired by Google because its capabilities were potentially useful to the core business. However, it was heavily siloed from the main HQ in California at first. This siloing gave the researchers to environment to produce many of the key innovations but caused it to hesitate entering the market when commercial pressure arose.
OpenAI, on the other hand, is HQed in San Francisco, California, with a highly influential leader, Sam Altman, and the entire network and talent pool of the Valley nearby.
OpenAI - Fast to Market, with Safety Governance Under Pressure

OpenAI was founded in 2015 by Sam Altman, Elon Musk, Greg Brockman, and others as a non-profit with the primary goal of ensuring that artificial general intelligence (AGI) benefits all of humanity.
In 2020, OpenAI published “Language Models are Few-Shot Learners,” introducing GPT-3, a 175-billion-parameter autoregressive language model, building off of the “Attention is all you Need” paper published in 2017. This was one of the first truly major, large-scale Large Language Models (LLMs).
However, as models were becoming more complex, AI safety became a concern. Former OpenAI employees including Dario and Daniela Amodei defected and founded Anthropic in 2021 to prioritize AI safety, alignment, and research.
To improve AI safety, OpenAI released a paper in 2022, “Training language models to follow instructions with human feedback” which used Reinforcement Learning with Human Feedback (RLHF). It demonstrated that humans are able to “teach” AI outputs that aligns with humans intention so that the AI can be trained more effectively. This paper demonstrated improvements in how humans can “guide” AI to produce output that aligns with its intentions.
On November 30, 2022, ChatGPT was officially released by OpenAI. It was intended to be introduced as a “research preview” and fast tracked to not let Anthropic get ahead. It quickly went viral, reaching one million users within a few days of its launch, the fastest growing consumer application ever at the time (Threads would later surpass this).
About a year later, the board was concerned about Sam Altman’s handling of AI safety and other allegations. The board abruptly fired Altman on November 17, 2023, citing concerns about his candor. But the move triggered a rapid employee and investor backlash: nearly all OpenAI employees threatened to leave unless he was reinstated, and Altman returned as CEO on November 22, 2023 with a restructured board.
Google DeepMind - Prioritizing AI safety, but Caught in the Innovators Dilemma

Google saw commercial potential in AI when it first acquired DeepMind because it recognized the strategic importance of AI in its core business.
At first, DeepMind’s culture leaned toward research depth, scientific credibility, and safety caution. It saw too much existential risk to let commercial priorities drive AI’s deployment, which made it slower to convert frontier models into consumer products. Demis wanted a path to spinout to a semi-independent Alphabet company, but ultimately didn’t due to the legal effort involved.
When OpenAI released GPT-3 in 2020, DeepMind did their own work on LLMs and published a few key papers, including Flamingo, Gato, and Chinchilla in 2022. In Sept 2022, it worked on Sparrow, DeepMind’s version of ChatGPT, which used RLHF. However, it was ultimately not released to the general public.
When OpenAI released ChatGPT, Google was briefly trapped by the innovators dilemma where it would put its brand at risk if it released an AI model too early and it hallucinated. During this time, a lot of DeepMind researchers were being poached by OpenAI who were frustrated by lack of progress by Google releasing a product.
On April 20, 2023, Google Brain (aimed at applied machine learning for Google products like TensorFlow) and DeepMind merged to form a single unit, Google DeepMind, to become one comprehensive unit.
Google DeepMind ultimately launched Gemini in Dec 2023 and upgraded versions that followed. While it is widely used nowadays and offers many benefits over ChatGPT (such as much larger context window for large documents), it ultimately suffered from the first mover advantage OpenAI had.
Key Technical Developments in modern AI
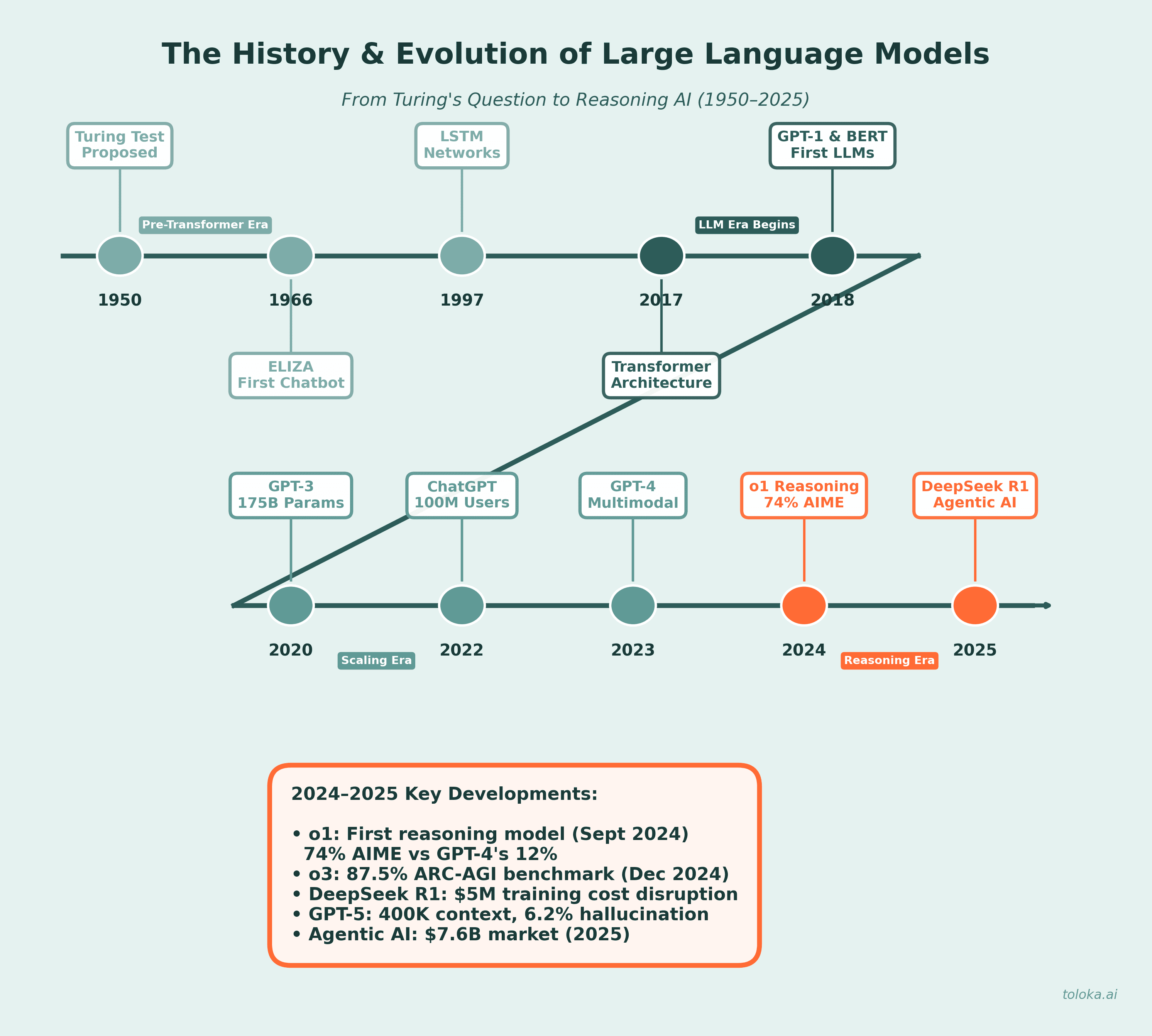
With that institutional backdrop in place, the technical story becomes easier to understand.
Next I’ll dive deeper into the key technical developments along the way to modern AI referenced in the book that approximate human intuitions. This is by no means a complete list since this book does not cover the more recent “reasoning era” Agentic AI.
Deep Reinforcement Learning (2013-2015)
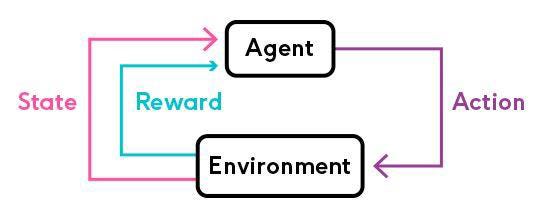
Reinforcement learning is a fairly intuitive, but math-heavy, ML method where an agent interacts with the world and periodically receives rewards / reinforcements that reflect how well its doing. Reinforcement learning is especially popular in environments where there are small number of training examples compared to the state space the agent exists in (like chess) that supervised learning would struggle in.
Each agent exists in an environment that resembles a Markov decision process, such as a maze, with other states that the agent can transition to. The agent has a policy that determines whether it will explore the environment or exploit an action with known outcomes. Each agent goes through several trials of decisions, determines which actions likely led to the desired outcomes, and updates its policies with what it learned.
One popular method of reinforcement learning is Q-learning (or Quality) where the agent estimates the max expected future reward for each action in each state. While Q learning is fairly primitive, it forms the basis for more sophisticated algorithms.
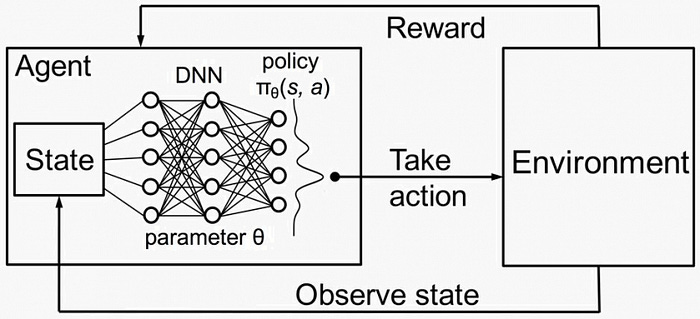
In a 2013 paper, “Playing Atari with Deep Reinforcement Learning”, Hassabis attempted to combine deep and reinforcement learning to create a single NN agent that is able to learn to play as many of the games as possible without knowing the rules in advance [1]. However, combining deep learning and reinforcement learning presented some challenges:
Deep learning applications require large amounts of hand-labelled training data (at the time). It also assumes samples to be independent.
RL algorithms, on the other hand, learn from a scalar reward signal that is frequently sparse, noisy and delayed. It also frequently encounters highly correlated states.
DeepMind used Deep Q-Networks (DQN) to play Atari games. They use a method of “experience replay” where the agent’s experiences are stored at each time step, then are sampled uniformly when performing updates. Randomizing samples helps break up correlations and allows the DNN to learn more effectively.
They demonstrate this approach on seven Atari Games (Beam Rider, Breakout, Enduro, Pong, Q*bert, Seaquest, and Space Invaders) and showed that it generalizes to a variety of games without specific information about each game.
Transformer (2017)
The Transformer architecture was introduced in the June 2017 seminal paper "Attention Is All You Need" by researchers from Google Brain and Google Research. It is widely considered one of the most important, consequential, and influential AI papers of the 21st century because it influences the architecture of Large Language Models we use today.
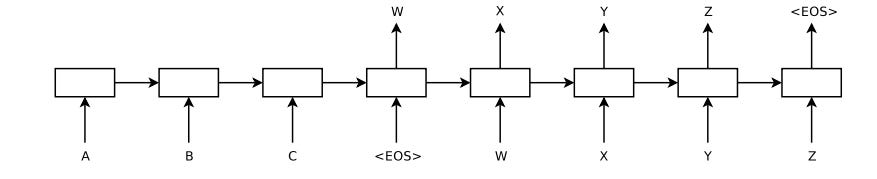
Prior to the transformer model, the standard approach for language training were Recurrent Neural Networks (RNNs) and sequence-to-sequence models with Long Short-Term Memory (LSTM). A RNN/LSTM processes words sequentially. This is useful in simple, condensed sentences structures such as subject-verb-object pairs. However, it suffers from modern sentences especially when meaning between words (both local and global context) are far away from each other in time.
The proposed “Attention” mechanism allows each word context into what other related words are doing. To get an idea for how the Attention mechanism works, lets consider real sentences.
Real sentences can have multiple parts of speech, with nouns (things), adjectives (modifiers to nouns), verbs (actions) and other parts of speech. Nouns can take on multiple meanings depending on the “context” is it in. Take the word “apple” in the following sentences:
Apple will release an iPhone next year.
I ate an apple and it was delicious.
In each sentence, its clear to us what “Apple” refers to: a company in the first sentence because of the world “IPhone” that provided context, and a fruit in the second because of the word, “delicious”. We humans used context clues to determine what “apple” means based on supporting words around it.
This is roughly what “Attention” enables mathematically in the Transformer architecture.
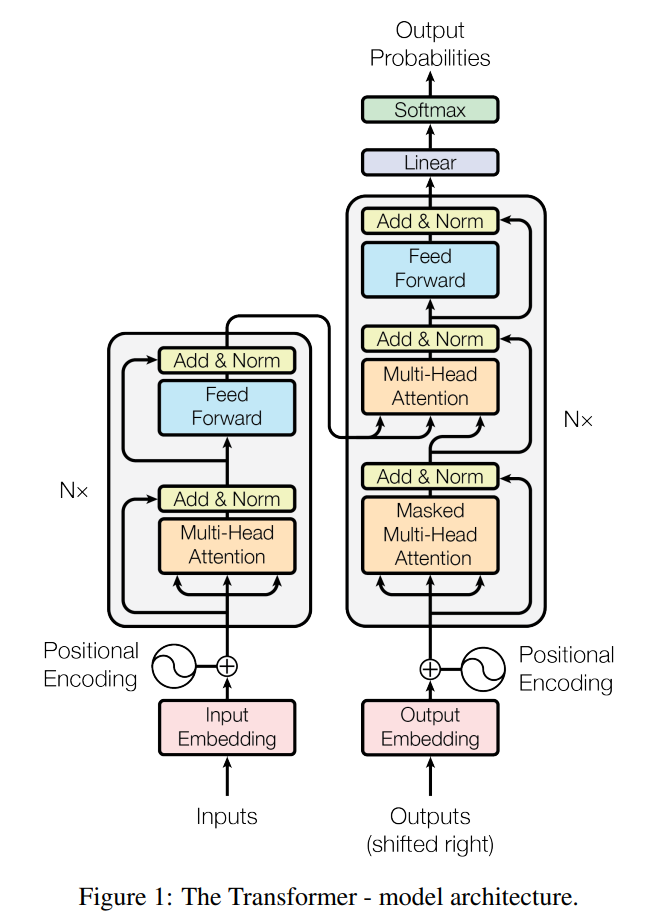
In the original Transformer, words are processed in parallel through attention layers rather than one step at a time as in RNNs. These words are broken down into several units called “tokens”.
Then, each token is converted to a high dimensional vector called an embedding that captures the meaning of each token. Think of this vector like the entries of a thesaurus where each tokens’ values corresponds to how strong it correlates to each entry in the thesaurus. A word like apple can map well on the the position that represents companies (such as Tesla, Exxon) and another position that specific fruits (oranges, pears). These embedding values are found during training on billions of words since each embedding has multiple “dimensions” it sits on.
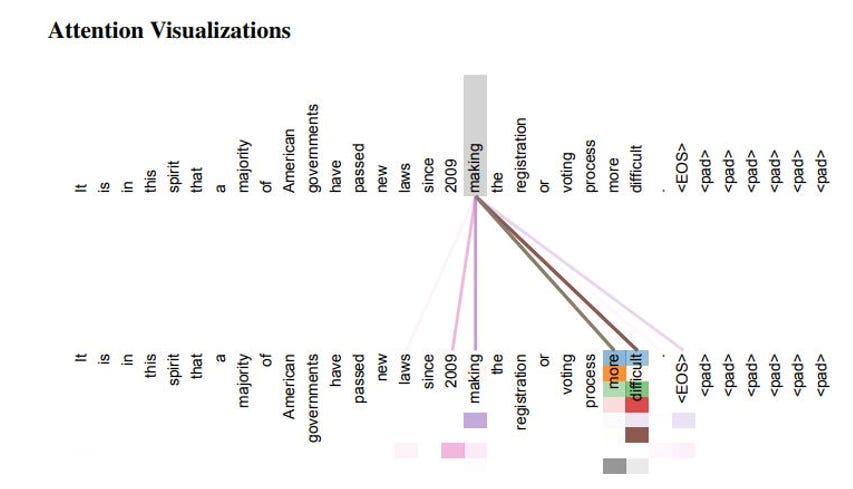
Then, through matrix operations, every word in a sentence calculates how much “attention” it should pay to every other word in that same sentence. This allows it to figure out relationship between words based on context clues.
To accomplish this, each embedding vector is decomposed into three vectors : Query (Q), Key (K), and Value (V). The query vector for each word is then multiplied by the key vectors for all the other words to come up with an “Attention” matrix that represents how related words are to each other. This attention value is given by the following formula:
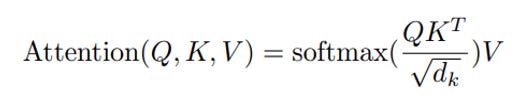
To predict the next word in the sequence, it uses a decoder to look at words in context to be able to generate the sequence of words that map well to the original meaning of the sentence.
AlphaFold 2 also showed how attention-like architectures could move beyond language: it used attention over sequence and pair representations to reason about relationships between amino acids, including residues far apart in the 1D sequence but close in 3D structure.
The transformer is significant because it is scalable along memory and compute:
The context window represents the “short term memory” as the maximum number of tokens (words) the model can “see” in one single look.
The main attention calculation is a matrix multiplication, so modern GPUs can parallelize these matrix multiplications to higher embedding dimensions.
Sentiment Neuron (2017)

The paper “Learning to Generate Reviews and Discovering Sentiment” was released by OpenAI on April 5, 2017. This paper was consequential because it became an early and memorable example of a neural network learning an internal representation that researchers did not explicitly program.
Originally, the researchers at OpenAI trained a specific type of RNN called an mLSTM (Multiplicative LSTM) on 82 million Amazon reviews with unsupervised language modeling. They found that one single neuron had essentially "volunteered" to track sentiment of whether parts of the review were positive, neutral, or negative.
This paper is considered highly influential to AI safety because it gave insight to researchers that certain neurons can be “inspected” to find big picture behavior and debug potentially dangerous behavior.
Few-shot and in-context learning in GPT-3 (2020)
Since the transformer paper was published, the standard approach for LLMs was to pretrain the models on a ton of data and fine tune the model for each specific task, such as reading comprehension and answering questions.

In Apr 2020, when OpenAI released GPT-3, it published a paper, “Language Models are Few-Shot Learners”. This paper presents “Few-shot learning” where a model learns to perform new tasks or recognize patterns simply by providing examples in the prompt, a capability known as in-context learning. It demonstrated that a generalized LLM model could be taught to solve new tasks using only a very small amount of training data. Other settings such as zero-shot and one-shot were shown with some accuracy loss compared to few-shot at the time.
Together, the Transformer architecture and GPT-3 helped make scaling a central paradigm in AI: as model size, data, and compute increased, capabilities improved in increasingly predictable ways.
Reinforcement Learning with Human Feedback (2022)
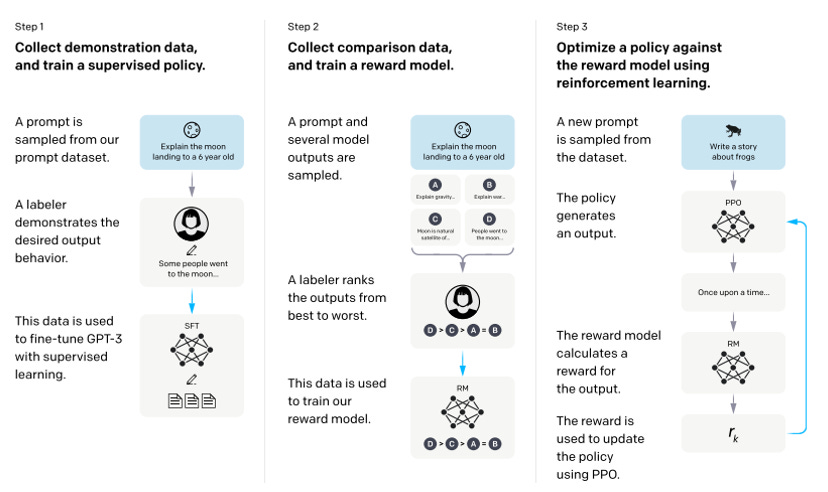
When LLMs began scaling in complexity, they sometimes generated outputs that were not aligned with their users, such as toxic or biased statements. The paper “Training language models to follow instructions with human feedback” used human-guided Reinforcement learning to “teach” the model what outputs are acceptable to humans.
OpenAI hired 40 contractors and trained a model, InstructGPT, with human feedback. They evaluated its responses vs GPT-3 and found that labelers significantly prefer InstructGPT outputs over outputs from GPT-3.
This procedure showed improvements in truthfulness and reducing toxicity. However, RLHF is hard to scale because human-provided feedback on AI is harder as AI generated more sophisticated outputs.
Chain-of-thought Prompting (2022)
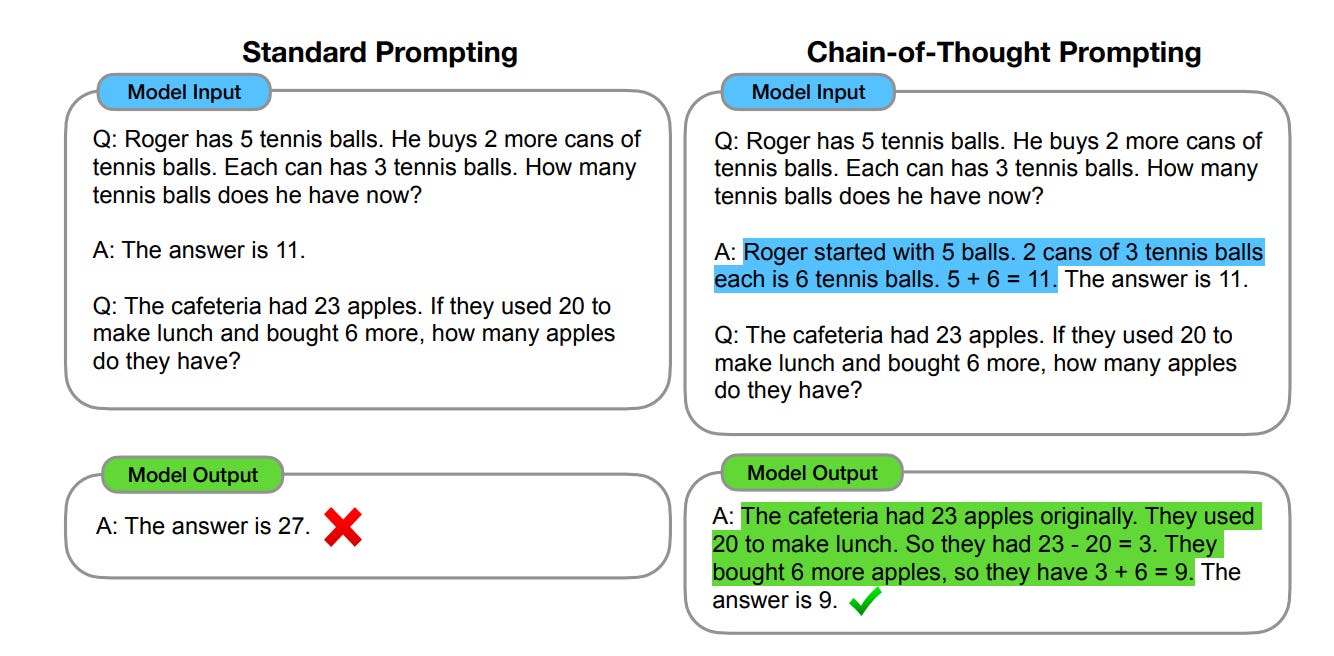
The concept of Chain-of-thought prompting was introduced in the 2022 paper, “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models”. CoT was a major demonstration that providing intermediate reasoning examples to pretrained LLMs can improve performance on arithmetic, commonsense, and symbolic reasoning tasks in sufficiently large models.
CoT also made model outputs more interpretable at the surface level, because humans could inspect the generated intermediate steps, though those steps should not be treated as a guaranteed faithful transcript of the model’s internal computation.
This approach is similar to how humans learn by analogy/example. It is typical for humans to decompose the problem into intermediate steps and solve each before giving the final answer. Most of us were taught to “show your work” when solving complex problems and were rewarded partial credit even though our answer might be wrong, since the line of reasoning can be valid up to a certain point.
Anthropic - Interpretability (2021-)

Anthropic was founded in 2021 by former OpenAI executives Dario and Daniela Amodei and other colleagues. It was established as a public benefit corporation (PBC) dedicated to AI safety, focusing on creating reliable, interpretable, and safe AI systems (like Claude) following disagreements over the rapid commercialization and safety approach at OpenAI.
Anthropic’s safety research pushed hard on mechanistic interpretability: trying to identify features, circuits, and internal representations that help explain why a model produced a given output.
This matters because interpretability is one possible path toward moving AI safety beyond trial-and-error behavior testing. Red teaming can reveal when a model fails from the outside; interpretability tries to understand why the model behaves that way from the inside.
Conclusion
Modern AI did not emerge from a single breakthrough, company, or personality. It came from the convergence of several technical ideas: deep reinforcement learning, transformers, scaling laws, RLHF, chain-of-thought prompting, and interpretability — with a set of organizational tensions that shaped how quickly those ideas moved from research labs into the hands of the public.
Demis Hassabis and Sam Altman represent two different archetypes in this story.
Hassabis reflects the research-driven, long-horizon pursuit of intelligence as a scientific problem.
Altman reflects the commercial, political, and go-to-market instincts required to turn frontier research into a mass-market product.
Both approaches have strengths and failure modes, and that tension is the real story of modern AI.
The next era of AI will likely be shaped not only by better models, but by how well institutions can balance those forces while building systems that are powerful, useful, and aligned with human intent.
If you want to continue expanding your knowledge on the HW side of AI, check out my other post:
An Overview of AI Accelerators: MAC Operations, DRAM/SRAM, Performance Metrics, and Architecture

I believe its important for people working around AI - ML engineers, semiconductor engineers, and end-users - to have a holistic understanding of AI, including the software interface and hardware underneath that optimizes calculations.
References
[1] Mnih, V, et al. “Playing Atari with Deep Reinforcement Learning” https://arxiv.org/pdf/1312.5602
[2] Sutskever, I, Vinyals, O, Le, Q. “Sequence to Sequence Learning with Neural Networks” https://arxiv.org/pdf/1409.3215
[3] Vaswani, A, et al. “Attention Is All You Need” https://arxiv.org/pdf/1706.03762
[4] Radford, A, Jozefowicz, R, Sutskever, I. “Learning to Generate Reviews and Discovering Sentiment” https://arxiv.org/pdf/1704.01444
[5] Brown, T, et al. “Language Models are Few-Shot Learners” https://arxiv.org/pdf/2005.14165
[6] Ouyang, L, et al. “Training language models to follow instructions with human feedback” https://arxiv.org/pdf/2203.02155
[7] Wei, J, et al. “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models” https://arxiv.org/pdf/2201.11903